개요
좀 더 복잡하고 다양한 포맷의 테이블 데이터 확보/생성
- 포맷 : 마크다운/ HTML
- 표 형태 : 병합, 표 안의 표 등등
1) 포맷
기본적으로 테이블 데이터의 형태는 크게 마크다운과 마크업 (HTML)으로 나뉨.
마크다운 ? HTML?
마크다운은 기본적으로 셀 병합이나 표 안의 표(중첩 테이블) 같은 복잡한 구조를 직접 지원하지 않음. 하지만
- HTML 태그를 함께 사용하거나
- 데이터를 여러 행으로 나누어 표현하는 방식
등으로 어느 정도 해결할 수 있음
📌 마크다운 vs HTML 비교 (LLM 관점)
| Markdown | ✅ 쉬움 | ✅ 간단한 행/열 구조 | ❌ 제한적 (병합, 중첩 불가) | ✅ 요약하기 좋음 |
| HTML | ❌ 상대적으로 어려움 | ✅ 강력한 구조 표현 | ✅ 병합, 중첩 가능 | ❌ 코드 분석 필요 |
이유
- 마크다운 테이블은 간단한 행과 열 구조로 되어 있어 빠르게 파싱 및 요약 가능.
- HTML 테이블은 rowspan, colspan 등의 속성이 있어 복잡한 레이아웃을 지원하지만, 모델이 분석하려면 추가적인 HTML 파싱이 필요함.
따라서 단순한 테이블 요약 작업이라면 Markdown이 더 빠르고 안정적, 병합된 셀을 정확하게 반영한 요약을 원하면 HTML이 필요할 수도 있음
👉 어떤 방식의 요약을 원하는지에 따라 포맷이 다르게 가져가는 것도 방법임.
- 단순한 데이터 요약 (Markdown 추천)
- 그룹화된 정보까지 반영한 요약 (HTML 고려)
결론
→ LLM 모델이 이해하기에는 마크다운(Markdown) 테이블이 더 좋을 가능성이 크다.
→ 복잡한 테이블이 필요하면 HTML을 활용해서 좀 더 확장된 형태로도 만들어서 사용해야 할 수도 있음.
→ HTML 테이블을 사용하면서도 요약을 쉽게 만들 방법 :
- HTML 테이블을 유지하면서
- rowspan, colspan을 분석하여 병합된 정보도 반영한 요약을 생성
같은 내용 마크다운 vs HTML 비교
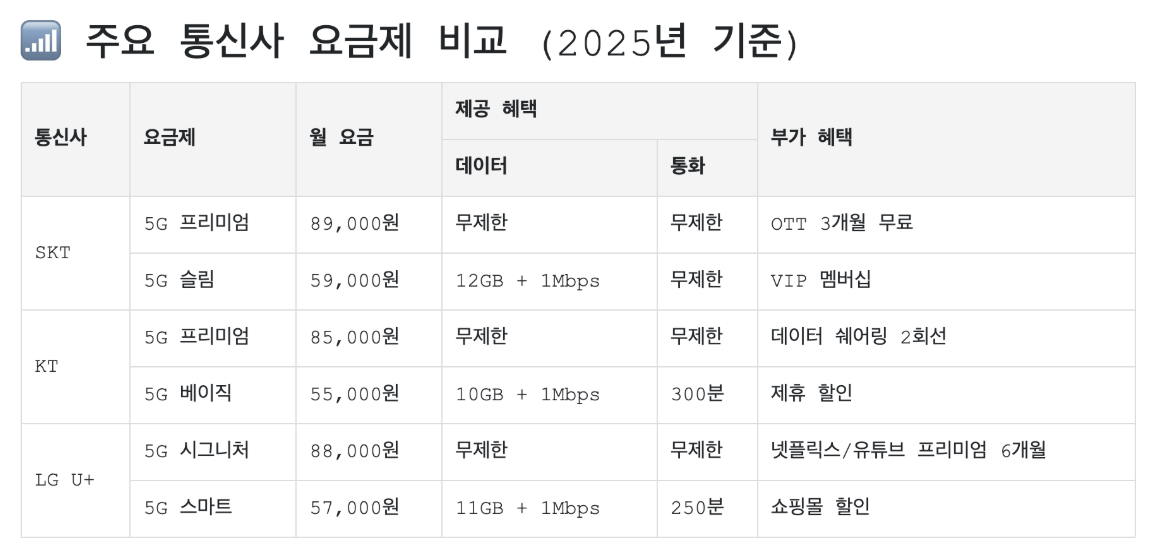
| 마크다운 | | 통신사 | 요금제 | 월 요금 | 데이터 | 통화 | 부가 혜택 | |---------|--------------|----------|------------------|---------|----------------------| | **SKT** | 5G 프리미엄 | 89,000원 | 데이터 무제한 | 무제한 | OTT 3개월 무료 | | **SKT** | 5G 슬림 | 59,000원 | 12GB + 1Mbps | 무제한 | VIP 멤버십 | | **KT** | 5G 프리미엄 | 85,000원 | 데이터 무제한 | 무제한 | 데이터 쉐어링 2회선 | | **KT** | 5G 베이직 | 55,000원 | 10GB + 1Mbps | 300분 | 제휴 할인 | | **LG U+** | 5G 시그니처 | 88,000원 | 데이터 무제한 | 무제한 | 넷플릭스/유튜브 프리미엄 6개월 | | **LG U+** | 5G 스마트 | 57,000원 | 11GB + 1Mbps | 250분 | 쇼핑몰 할인 | |
| HTML | <table border="1"> <thead> <tr> <th>통신사</th> <th>요금제</th> <th>월 요금</th> <th>데이터</th> <th>통화</th> <th>부가 혜택</th> </tr> </thead> <tbody> <tr> <td><strong>SKT</strong></td> <td>5G 프리미엄</td> <td>89,000원</td> <td>데이터 무제한</td> <td>무제한</td> <td>OTT 3개월 무료</td> </tr> <tr> <td><strong>SKT</strong></td> <td>5G 슬림</td> <td>59,000원</td> <td>12GB + 1Mbps</td> <td>무제한</td> <td>VIP 멤버십</td> </tr> <tr> <td><strong>KT</strong></td> <td>5G 프리미엄</td> <td>85,000원</td> <td>데이터 무제한</td> <td>무제한</td> <td>데이터 쉐어링 2회선</td> </tr> <tr> <td><strong>KT</strong></td> <td>5G 베이직</td> <td>55,000원</td> <td>10GB + 1Mbps</td> <td>300분</td> <td>제휴 할인</td> </tr> <tr> <td><strong>LG U+</strong></td> <td>5G 시그니처</td> <td>88,000원</td> <td>데이터 무제한</td> <td>무제한</td> <td>넷플릭스/유튜브 프리미엄 6개월</td> </tr> <tr> <td><strong>LG U+</strong></td> <td>5G 스마트</td> <td>57,000원</td> <td>11GB + 1Mbps</td> <td>250분</td> <td>쇼핑몰 할인</td> </tr> </tbody> </table> |
2) 병합된 표
2-1) GPT한테 생성 지시
생성된 데이터 예시
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>통신사 요금제 비교</title>
<style>
table {
width: 100%;
border-collapse: collapse;
text-align: center;
}
th, td {
border: 1px solid #ddd;
padding: 10px;
}
th {
background-color: #f4f4f4;
}
</style>
</head>
<body>
<h2>📶 주요 통신사 요금제 비교 (2025년 기준)</h2>
<table>
<thead>
<tr>
<th rowspan="2">통신사</th>
<th rowspan="2">요금제</th>
<th rowspan="2">월 요금</th>
<th colspan="2">제공 혜택</th>
<th rowspan="2">부가 혜택</th>
</tr>
<tr>
<th>데이터</th>
<th>통화</th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan="2">SKT</td>
<td>5G 프리미엄</td>
<td>89,000원</td>
<td>무제한</td>
<td>무제한</td>
<td>OTT 3개월 무료</td>
</tr>
<tr>
<td>5G 슬림</td>
<td>59,000원</td>
<td>12GB + 1Mbps</td>
<td>무제한</td>
<td>VIP 멤버십</td>
</tr>
<tr>
<td rowspan="2">KT</td>
<td>5G 프리미엄</td>
<td>85,000원</td>
<td>무제한</td>
<td>무제한</td>
<td>데이터 쉐어링 2회선</td>
</tr>
<tr>
<td>5G 베이직</td>
<td>55,000원</td>
<td>10GB + 1Mbps</td>
<td>300분</td>
<td>제휴 할인</td>
</tr>
<tr>
<td rowspan="2">LG U+</td>
<td>5G 시그니처</td>
<td>88,000원</td>
<td>무제한</td>
<td>무제한</td>
<td>넷플릭스/유튜브 프리미엄 6개월</td>
</tr>
<tr>
<td>5G 스마트</td>
<td>57,000원</td>
<td>11GB + 1Mbps</td>
<td>250분</td>
<td>쇼핑몰 할인</td>
</tr>
</tbody>
</table>
</body>
</html>
2-2) 기존 데이터셋 리서치
금융, 법률 문서 기계독해 데이터셋
금융 및 법률 분야 전문문서를 활용하여 기계독해 모델 생성을 위한 지문-질문-답변으로 구성된 데이터셋
https://huggingface.co/datasets/shchoice/finance-legal-mrc/viewer/tableqa
shchoice/finance-legal-mrc · Datasets at Hugging Face
<table><tbody><tr><td colspan="2">구분</td><td>SKT</td><td>KT</td><td>LGT</td><td>계</td></tr><tr><td rowspan="3">이동통신</td><td>2G</td><td>11,615,064</td><td>2,908,504</td><td>6,043,681</td><td>20,567,249</td></tr><tr><td>3G</td><td>12,654,489</t
huggingface.co
- 테이블 QA 데이터 총 약 10만건 (108k)
- train : 96,000 / test : 12,000
- 테이블 QA에 필요한 정보로 구성되어 있으며 아래 2가지 데이터 활용 가능해보임.
- table_title: 표의 제목
- table_html: 표의 HTML 데이터
- 데이터 로드시 “tableqa” 선택해서 테이블 데이터만 로드 가능
from datasets import load_dataset
# 특정 configuration의 특정 split 로드 - tableqa
train_data = load_dataset("shchoice/finance-legal-mrc", "tableqa", split="train")
valid_data = load_dataset("shchoice/finance-legal-mrc", "tableqa", split="test")
# 특정 configuration의 전체 split 로드 - tableqa
full_dataset = load_dataset("shchoice/finance-legal-mrc", "tableqa")
데이터셋 예시
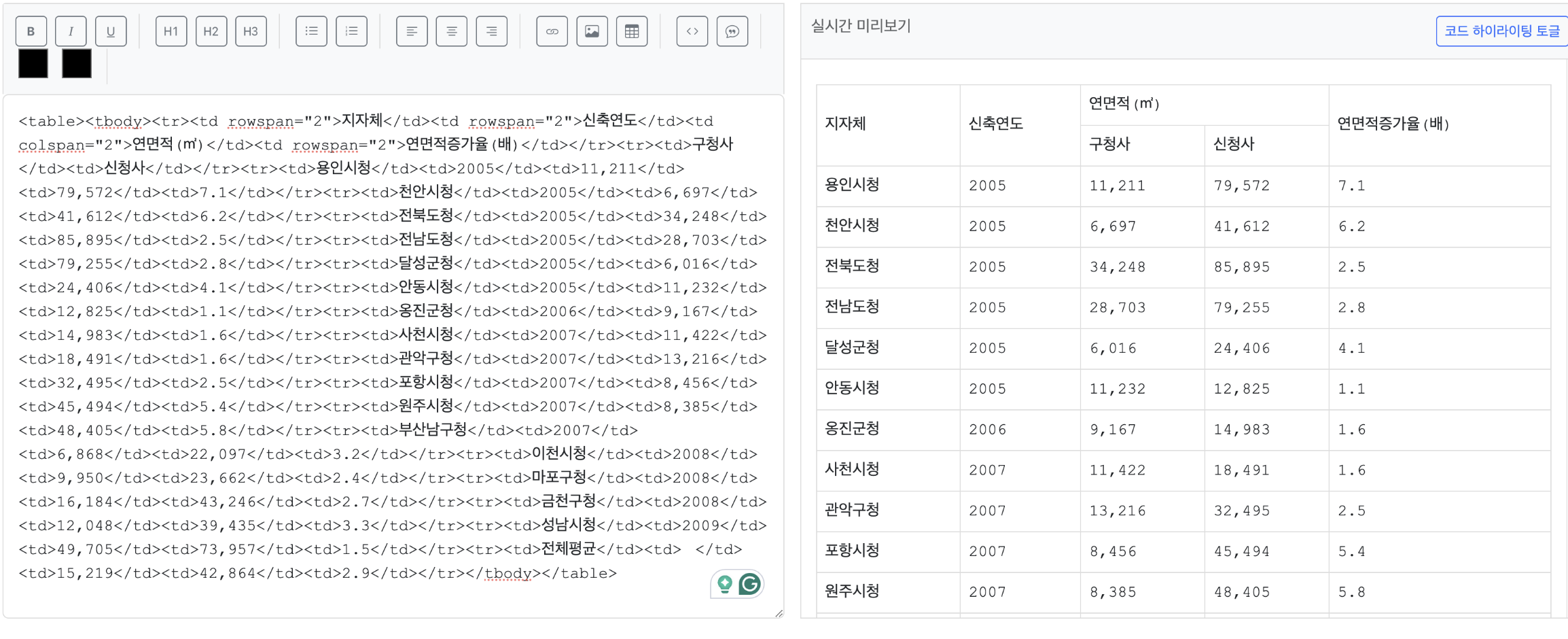
2-3) 테이블 병합 여부 체크
테이블에 병합된 부분 있는지 체크 후 병합된 경우 따로 저장 (이미지도 함께 저장)
→ table_title이 고유한 테이블 데이터에 대해 병합된 부분이 있는 경우 따로 저장하고 이미지로도 저장하는 모듈 개발
→ table_title이 고유한 테이블 데이터는 전체 데이터의 약 10% 가량
- train - table_title이 고유한 테이블 데이터 : 총 9,388건 / 전체 96,000건
- test - table_title이 고유한 테이블 데이터 : 총 1,197건 / 전체 12,000건
- 병합된 테이블이 있는 데이터 : 총 6,276건 (train : 5,533건 / test : 743건)
- 데이터 경로
- train: src/tableInfoGen/data/finance-legal-mrc/json/merged_table_train_data.json
- test: src/tableInfoGen/data/finance-legal-mrc/json/merged_table_test_data.json
데이터 예시
- { "table_title": "[표 1] 스마트폰 단말기 개통현황", "table_html": "<table><tbody><tr><td colspan=\"2\">구분</td><td>SKT</td><td>KT</td><td>LGT</td><td>계</td></tr><tr><td rowspan=\"3\">이동통신</td><td>2G</td><td>11,615,064</td><td>2,908,504</td><td>6,043,681</td><td>20,567,249</td></tr><tr><td>3G</td><td>12,654,489</td><td>12,107,691</td><td>2,614,793</td><td>27,376,973</td></tr><tr><td>계</td><td>24,269,553</td><td>15,016,195</td><td>8,614,793</td><td>47,944,222</td></tr><tr><td rowspan=\"4\">스마트폰</td><td>2G</td><td>43,363</td><td>0</td><td>81,462</td><td>124,825</td></tr><tr><td>3G</td><td>411,940</td><td>504,264</td><td>0</td><td>916,204</td></tr><tr><td>계</td><td>455,303</td><td>504,264</td><td>81,462</td><td>1,041,029</td></tr><tr><td>종류</td><td>18종</td><td>9종</td><td>2종</td><td>29종</td></tr></tbody></table>"
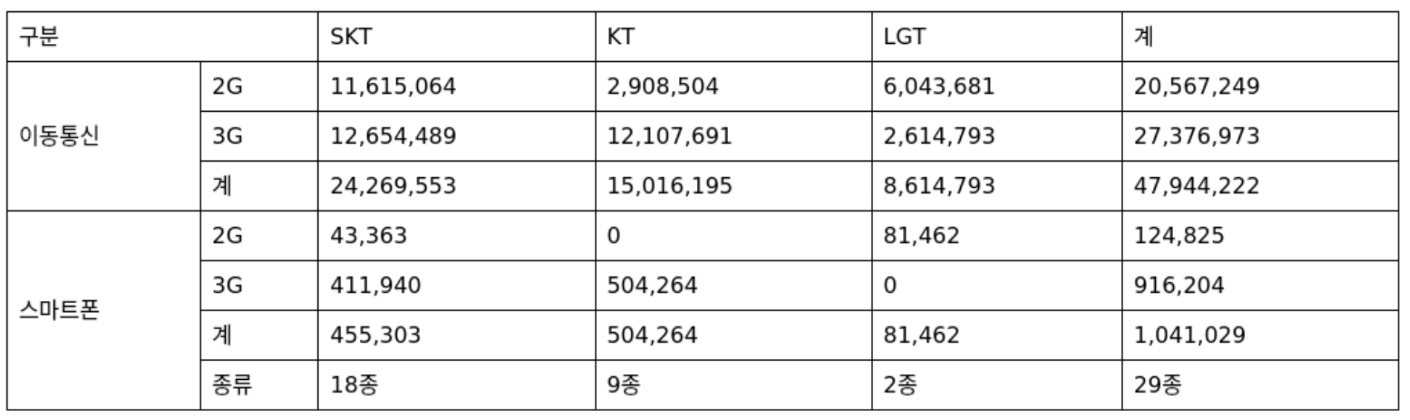
- 이미지 저장한 데이터 : 1458건 (메모리 효율화를 위해 일부만 저장)
변한환 데이터셋
https://huggingface.co/datasets/didi0di/finance-legal-mrc_merged-table
didi0di/finance-legal-mrc_merged-table · Datasets at Hugging Face
<table><tbody><tr><td rowspan="2"></td><td colspan="2">기존 미납 (A)</td><td colspan="2">신규 부과 (B)</td><td colspan="2">징수 완료 (C)</td><td colspan="2">미납소계...
huggingface.co
'AI > LLM' 카테고리의 다른 글
| [LLM] Linux nvidia gpu 메모리 초기화 (2) | 2024.10.22 |
|---|---|
| [LLM] ollama 사용하기 (0) | 2024.08.13 |
| [RAG] RAG 벤치마크 데이터셋 & 성능 평가 리뷰 : RAG-Evaluation-Dataset-KO (0) | 2024.07.16 |
| [RAG] LLM-based Query Rewriting 논문 리뷰 (1) Enhancing Conversational Search: Large Language Model-Aided Informative Query Rewriting (0) | 2024.05.08 |
| [LLM] 왔다, LLaMA3! (2) | 2024.04.19 |




댓글