개요
한국어 RAG 솔루션 성능 평가를 위해 RAG 벤치마크 데이터셋과 평가 관련 리서치를 진행,
올거나이즈에서 운영중인 RAG 리더보드에서 사용하는 벤치마크 데이터셋을 찾게 되었다.
https://huggingface.co/datasets/allganize/RAG-Evaluation-Dataset-KO
allganize/RAG-Evaluation-Dataset-KO · Datasets at Hugging Face
미국, 중국, 한국의 주식 시장에 대한 성과 및 선호도의 예상 순서는 다음과 같은 요소를 기반으로 할 수 있습니다. 이러한 예상은 각 국의 경제 상황, 시장의 성숙도, 정치적 안정성, 기술 혁신,
huggingface.co
해당 벤치마크 데이터셋과 제공하는 LLM 기반 자동평가 코드를 사용하면
리더보드 내 다른 RAG 솔루션들과 성능을 비교할 수 있을 것 같아 사용해보았다.
5개 도메인(금융, 공공, 의료, 법률, 커머스)에 대해서 한국어 RAG의 성능을 평가할 수 있다.
해당 벤치마크 데이터셋으로 평가한 결과는 다음과 같다고한다.

Allganize RAG 리더보드에서는 문서를 업로드하고, 자체적으로 만든 질문을 사용해 답변을 얻었습니다.생성한 답변과 정답 답변을 자동 성능 평가 방법을 적용해 각 RAG 방법별 성능 측정을 했습니다.
RAG Leaderboard의 결과는 영어로만 답변을 생성한 경우, 정답에서 제외시켰습니다.생성 답변에 한국어가 하나라도 들어있을 경우는, 한국어 답변으로 포함시켰습니다.
리더보드에 올리면 자동으로 평가를 해주는데,
나는 회사 내부에 있는 RAG 솔루션의 평가를 하려고 하는 것이라
벤치마크 데이터셋과 자동평가 코드를 이용해서 직접 평가를 수행했다.
Auto Evaluate
성능 평가 방법은 RAG에서 생성한 답변과 정답 답변을 기반으로 LLM을 사용해 평가합니다.
총 5개의 LLM Eval을 사용했습니다.
각 LLM Eval을 사용해 5개의 평가 결과 중 O가 3개 이상인 경우 O으로, 2개 이하이면 X로 평가했습니다.
- RAGAS : answer_correctness (threshold=0.6)
- TonicAI : answer_similarity (threshold=4)
- MLflow : answer_similarity/v1/score (threshold=4)
- MLflow : answer_correctness/v1/score (threshold=4)
- Allganize Eval : answer_correctness/claude3-opus
LLM 기반 평가 방법이기 때문에, 오차율이 존재합니다.
Finance 도메인을 기반으로 사람이 평가한 것과 오차율을 비교하였을 때, 약 8%의 오차율을 보였습니다.
Colab에 5개 평가 방법을 각각 사용할 수 있게 정리하였습니다.
Dataset
Domain
다양한 도메인 중, 다섯개를 선택해 성능 평가를 진행했습니다.
- finance(금융)
- public(공공)
- medical(의료)
- law(법률)
- commerce(커머스)
Documents
도메인별로 PDF 문서를 수집하여 질문들을 생성했습니다.
각 도메인별 문서의 페이지 수 총합이 2~300개가 되도록 문서들을 수집했습니다.
각 문서의 이름, 페이지 수, 링크 또한 documents.csv 파일을 다운받으면 확인하실 수 있습니다.
각 도메인별 pdf 문서 갯수는 다음과 같습니다.
- finance: 10개 (301 page) -> 해당 도메인에 대해서만 평가를 수행함.
- public: 12개 (258 page)
- medical: 20개 (276 page)
- law: 12개 (291 page)
- commerce: 9개 (211 page)
Question and Target answer
문서의 페이지 내용을 보고 사용자가 할만한 질문 및 답변들을 생성했습니다.
각 도메인별로 60개의 질문들을 가지고 있습니다.
실제 평가
데이터셋
아래 금융 도메인 문서 10개, 질문 60개에 대해서만 평가를 진행했다.
직접 링크에 들어가서 다운받았고, 다운 받은 문서는 여기 모아놨다.
평가 코드
평가 코드는 colab에 공개된 코드를 조금 수정해 사용했다.
코드를 그대로 돌리게 되면, RAGAS 실행에서 ExceptionInRunner 에러가 난다.
ExceptionInRunner: The runner thread which was running the jobs raised an exeception.
아래 웹사이트에서
while using gpt use ragas==0.1.4 langchain==0.1.5 it worked for me
라는 코멘트를 보고, ragas==0.1.4 로 다시 설치했더니 에러가 해결되었다.
https://github.com/explodinggradients/ragas/issues/735
Error in Testset Generation - ExceptionInRunner: The runner thread which was running the jobs raised an exeception. · Issue #73
[X] I have checked the documentation and related resources and couldn't resolve my bug. Describe the bug test_generator.generate_with_langchain_docs() returns RuntimeError. Please note i am using V...
github.com
데이터셋 로드 및 확인
- 실제로 평가하려고 하는 question
- 평가 대상 RAG 솔루션이 생성한 답변
- 정답 Answer

데이터를 확인하고, 샘플 데이터 대신 테스트하고 싶은 데이터셋으로 바꿔준다.
# question_list = ["2024년 1월, 2월, 3월 각각의 평균 조달금리와 응찰률이 어떻게 되나요?", "2024년 1월, 2월, 3월 각각의 평균 조달금리와 응찰률이 어떻게 되나요?"]
# generated_answer_list = ["2024년 1월의 평균 조달금리는 3.27%, 응찰률은 333%입니다. 2월의 평균 조달금리는 3.36%, 응찰률은 335%입니다. 3월의 평균 조달금리는 3.32%, 응찰률은 334%입니다[2].", "2024년 1월, 2월, 3월의 평균 조달 금리는 각각 3.57%, 3.52%, 3.32% 입니다. 응찰률은 각각 271%, 285%, 334% 입니다."]
# target_answer_list = ["2024년 1월의 평균 조달금리는 3.27%, 응찰률은 333이며, 2월의 평균 조달금리는 3.36%, 응찰률은 335이며, 3월의 평균 조달금리는 3.32%, 응찰률은 334입니다.", "2024년 1월의 평균 조달금리는 3.27%, 응찰률은 333%입니다. 2월의 평균 조달금리는 3.36%, 응찰률은 335%입니다. 3월의 평균 조달금리는 3.32%, 응찰률은 334%입니다[2]."]
question_list = df['question'].to_list()
generated_answer_list = df['RAG42_answer'].to_list()
target_answer_list = df['target_answer'].to_list()
이제 실제로 평가를 해볼 건데,
LLM 기반 자동평가이고, 평가 모델로 GPT와 Claude3를 이용하기 때문에
OpenAI API Key 와 Anthropic API Key 가 필요하다.
보통 LLM 기반 자동평가면 GPT를 쓰는데 (G-Eval, MT-Bench 등)
다 GPT를 쓰는 것도 아니고 왜 하나는 Claude3 인가 했더니
마지막 평가 방법인 Allganize Eval (올거나이즈가 자체로 개발한 듯) 에서 Claude를 사용해서 평가를 진행하더라는.
Anthropic 같은 경우에는 신규 가입시 5달러를 무료로 줘서 이걸로 평가를 진행해보았다.
API 키 발급은 아래 사이트 참고.
https://docs.anthropic.com/ko/docs/getting-access-to-claude
Claude 액세스 권한 얻기 - Anthropic
Claude 액세스 권한 얻기
docs.anthropic.com
발급 받고 나서, 크레딧 활성화를 해줘야 한다.

휴대폰 번호 넣고,
인증번호 입력하면 크레딧 활성화 완료!
5달러가 잘 충전되어 있는 것을 확인했다.
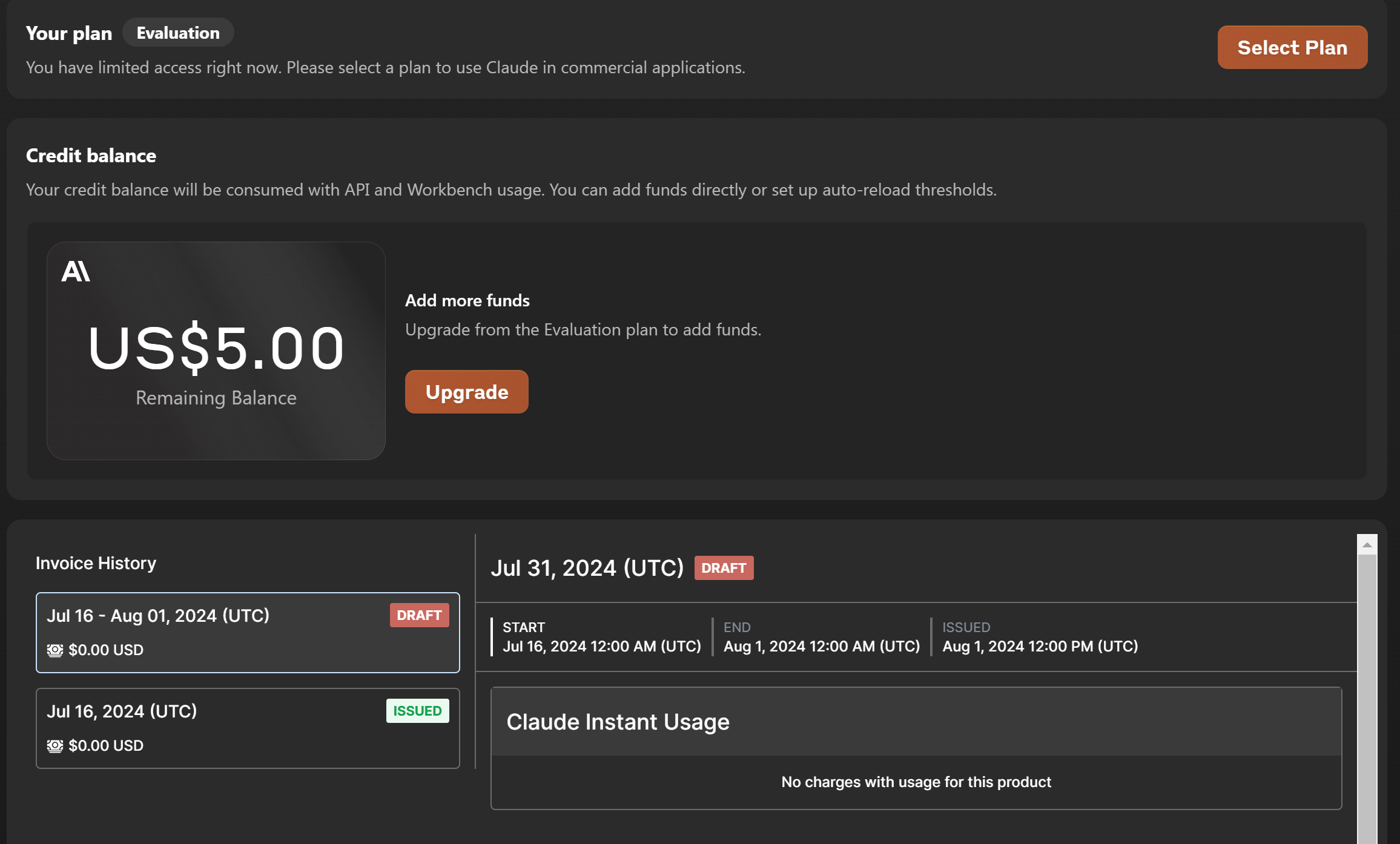
이제 실제로 평가를 시작해보자!
1. RAGAS : answer_correctness
data_samples = {
'question': question_list,
'answer': generated_answer_list,
'ground_truth': target_answer_list
}
dataset = Dataset.from_dict(data_samples)
ragas_score = evaluate(dataset, metrics=[answer_correctness])
ragas_score = ragas_score.to_pandas()
ragas_answer_correctness = ["O" if ele > 0.6 else "X" for ele in ragas_score["answer_correctness"].tolist()]
print(ragas_answer_correctness)
# 평가 결과
>>> ['O', 'O', 'O', 'X', 'X', 'X', 'O', 'X', 'O', 'O', 'O', 'O', 'O', 'X', 'O', 'O', 'O', 'O', 'O', 'O', 'X', 'O', 'O', 'X', 'X', 'O', 'O', 'O', 'X', 'X', 'O', 'X', 'X', 'X', 'O', 'O', 'O', 'X', 'X', 'O', 'X', 'X', 'X', 'X', 'O', 'O', 'O', 'O', 'O', 'O', 'X', 'O', 'O', 'O', 'X', 'X', 'X', 'O', 'O', 'X']
LLM이 평가한 결과가 ragas_answer_correctness 리스트에 담긴 것을 확인해 볼 수 있다.
아래는 실제 실행창.

2. TonicAI : answer_similarity
def get_llm_response(question_index):
return {
"llm_answer": generated_answer_list[question_index],
"llm_context_list": [""]
}
scorer = ValidateScorer()
tonic_answer_similarity = []
for i, question in enumerate(question_list):
benchmark = Benchmark(questions=[question], answers=[target_answer_list[i]])
run = scorer.score(benchmark, lambda q: get_llm_response(i))
tonic_score = run.run_data[0].scores["answer_similarity"]
tonic_answer_similarity.append("O" if tonic_score > 3.0 else "X")
print(tonic_answer_similarity)
# 평가 결과
>>>['O', 'O', 'X', 'O', 'X', 'X', 'O', 'X', 'O', 'X', 'X', 'O', 'O', 'O', 'O', 'O', 'O', 'X', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'X', 'X', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'X', 'X', 'O', 'O', 'X', 'O', 'O', 'O', 'O', 'O', 'X', 'X', 'X', 'X', 'O', 'X', 'X']
이거 좀 오래걸린다.

3. MLflow
3, 4번 항목이 둘다 MLflow를 이용해서 평가하는거라 한 번에 확인 가능.
mlflow_eval_data = pd.DataFrame({"inputs": question_list, "predictions": generated_answer_list, "ground_truth": target_answer_list})
with mlflow.start_run() as run:
results = mlflow.evaluate(
data=mlflow_eval_data,
targets="ground_truth",
predictions="predictions",
extra_metrics=[mlflow.metrics.genai.answer_similarity(), mlflow.metrics.genai.answer_correctness()],
evaluators="default",
)
eval_table = results.tables["eval_results_table"]
mlflow_answer_similarity = eval_table["answer_similarity/v1/score"].tolist()
mlflow_answer_correctness = eval_table["answer_correctness/v1/score"].tolist()
mlflow_answer_similarity = ["O" if ele > 3 else "X" for ele in mlflow_answer_similarity]
mlflow_answer_correctness = ["O" if ele > 3 else "X" for ele in mlflow_answer_correctness]
print(mlflow_answer_similarity)
print(mlflow_answer_correctness)
# 평가 결과 - 3번 항목
>>> ['O', 'O', 'X', 'O', 'X', 'X', 'X', 'X', 'O', 'X', 'X', 'O', 'X', 'X', 'O', 'X', 'X', 'X', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'X', 'X', 'O', 'O', 'O', 'O', 'O', 'X', 'O', 'X', 'O', 'O', 'O', 'O', 'X', 'O', 'O', 'O', 'O', 'X', 'O', 'O', 'X', 'O', 'X', 'O', 'O', 'O', 'X', 'X', 'O', 'X', 'X', 'X', 'X']
# 평가 결과 - 4번 항목
>>> ['O', 'O', 'X', 'O', 'X', 'X', 'X', 'X', 'O', 'X', 'X', 'O', 'X', 'X', 'O', 'X', 'X', 'X', 'O', 'O', 'X', 'O', 'O', 'O', 'O', 'X', 'X', 'O', 'O', 'O', 'O', 'X', 'X', 'O', 'X', 'O', 'O', 'O', 'O', 'X', 'O', 'O', 'O', 'O', 'X', 'O', 'O', 'X', 'O', 'X', 'O', 'O', 'O', 'X', 'X', 'O', 'X', 'X', 'X', 'X']

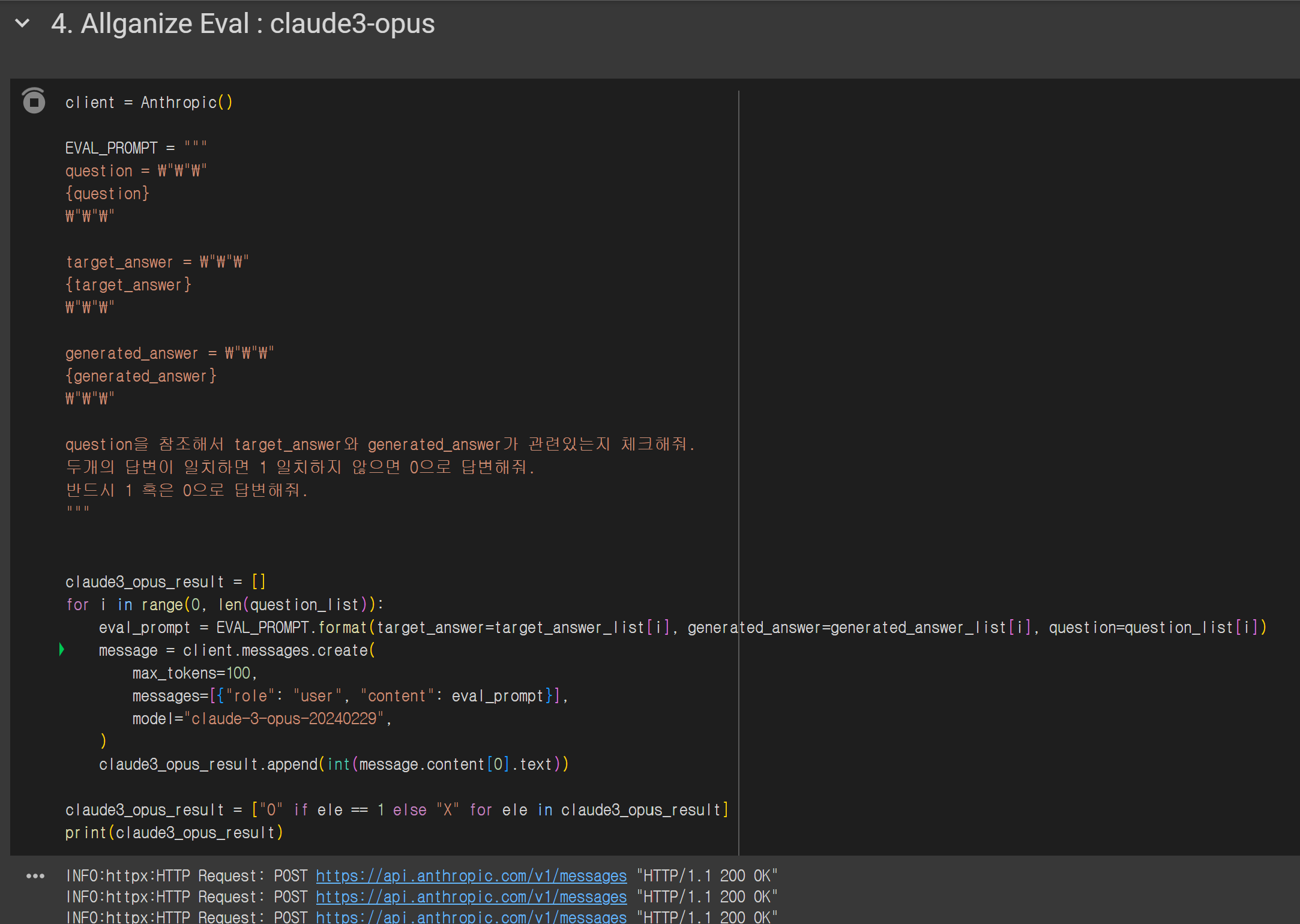
4. Allganize Eval : claude3-opus
client = Anthropic()
EVAL_PROMPT = """
question = \"\"\"
{question}
\"\"\"
target_answer = \"\"\"
{target_answer}
\"\"\"
generated_answer = \"\"\"
{generated_answer}
\"\"\"
question을 참조해서 target_answer와 generated_answer가 관련있는지 체크해줘.
두개의 답변이 일치하면 1 일치하지 않으면 0으로 답변해줘.
반드시 1 혹은 0으로 답변해줘.
"""
claude3_opus_result = []
for i in range(0, len(question_list)):
eval_prompt = EVAL_PROMPT.format(target_answer=target_answer_list[i], generated_answer=generated_answer_list[i], question=question_list[i])
message = client.messages.create(
max_tokens=100,
messages=[{"role": "user", "content": eval_prompt}],
model="claude-3-opus-20240229",
)
claude3_opus_result.append(int(message.content[0].text))
claude3_opus_result = ["O" if ele == 1 else "X" for ele in claude3_opus_result]
print(claude3_opus_result)
# 평가 결과
>>>['X', 'O', 'X', 'O', 'X', 'X', 'X', 'X', 'X', 'X', 'X', 'O', 'O', 'O', 'O', 'X', 'X', 'X', 'O', 'O', 'X', 'O', 'O', 'O', 'O', 'X', 'X', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'X', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'X', 'X', 'O', 'O', 'X', 'O', 'X', 'O', 'O', 'O', 'X', 'X', 'X', 'O', 'X', 'X', 'X']
5. Ensemble
마지막으로 위에서 실행한 5개 평가 결과를 종합해서 최종 평가를 내는 부분이다.
3개 이상 O가 나와야 최종적으로 O라고 평가한다.
def vote(lst, threshold):
counts = Counter(lst)
if counts.get("O", 0) >= threshold:
return "O"
else:
return "X"
total_result = []
for i in range(0, len(claude3_opus_result)):
ensem_list = [ragas_answer_correctness[i], tonic_answer_similarity[i], mlflow_answer_correctness[i], mlflow_answer_similarity[i], claude3_opus_result[i]]
result = vote(ensem_list, threshold=3)
total_result.append(result)
print(total_result)
# 평가 결과
>>>['O', 'O', 'X', 'O', 'X', 'X', 'X', 'X', 'O', 'X', 'X', 'O', 'O', 'X', 'O', 'X', 'X', 'X', 'O', 'O', 'X', 'O', 'O', 'O', 'O', 'X', 'X', 'O', 'O', 'O', 'O', 'O', 'X', 'O', 'X', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'X', 'X', 'O', 'O', 'X', 'O', 'X', 'O', 'O', 'O', 'X', 'X', 'X', 'X', 'X', 'X', 'X']
정답이 총 33개로 나온다.
O 라고 나온 값들을 1로 계산해서 최종 성능은 0.55 인것으로 확인. (33/60)
'AI > LLM' 카테고리의 다른 글
| [LLM] Linux nvidia gpu 메모리 초기화 (2) | 2024.10.22 |
|---|---|
| [LLM] ollama 사용하기 (0) | 2024.08.13 |
| [RAG] LLM-based Query Rewriting 논문 리뷰 (1) Enhancing Conversational Search: Large Language Model-Aided Informative Query Rewriting (0) | 2024.05.08 |
| [LLM] 왔다, LLaMA3! (2) | 2024.04.19 |
| [한국어 LLM 벤치마크] Korean MT-bench score 계산하기 (2) (0) | 2024.04.15 |




댓글