배경
QA 데이터셋을 만들던 중,
기간 내 목표 수량을 채우기 위해
LLM으로 Query를 paraphrasing해 데이터를 증강하는 방식으로 데이터를 생성하게 되었다.
Origical Query와 paraphrasing한 Query를 놓고 보니
어느 정도는 유사해야 하지만 그렇다고 너무 유사하면 모델 학습에 의미가 없을 것 같았다.
그래서 paraphrasing한 Query를 검수하는 후처리 단계를 하나 추가해야 겠다고 생각했는데,
2가지 방법 정도가 떠올랐다.
LLM으로 paraphrasing한 Query를 검수하는 방법
1) 임베딩 모델을 통한 문장 유사도를 계산하고, 특정 treshold 범위를 정해서 해당 범위에 포함되는 쿼리만 사용
2) LLM으로 검수
우선 1번을 시도해보았다.
임베딩 모델로는 Sentence BERT와 BGE-M3를 사용했다.
문장 유사도에 관한 자세한 내용은 아래 허깅페이스 설명 참조.
https://huggingface.co/tasks/sentence-similarity
What is Sentence Similarity? - Hugging Face
💻 Gradio-Blocks/Ask_Questions_To_YouTube_Videos
huggingface.co
처음에는 간단하게 UI로 테스트 해볼 수 있는 아래 허깅페이스 API 제공 모델로 테스트를 해봤다.
https://huggingface.co/BAAI/bge-m3
BAAI/bge-m3 · Hugging Face
For more details please refer to our github repo: https://github.com/FlagOpen/FlagEmbedding In this project, we introduce BGE-M3, which is distinguished for its versatility in Multi-Functionality, Multi-Linguality, and Multi-Granularity. Multi-Functionalit
huggingface.co
이렇게 UI로 대상 문장과 여러 문장과의 문장 유사도를 계산해 볼 수 있다.
처음에 모델 로드하는데 시간이 좀 걸린다.
대신 한번 로드를 하고 나면 그 다음부터는 속도가 빨라진다.
유사도 계산이 완료되었다.

딱 봐도 단순 키워드 위주로 중복되는 단어가 많은 2번째 문장 같은 경우 유사도가 굉장히 높게 나왔다.
좀 연관성이 떨어져 보이는 문장도 추가해보았다.
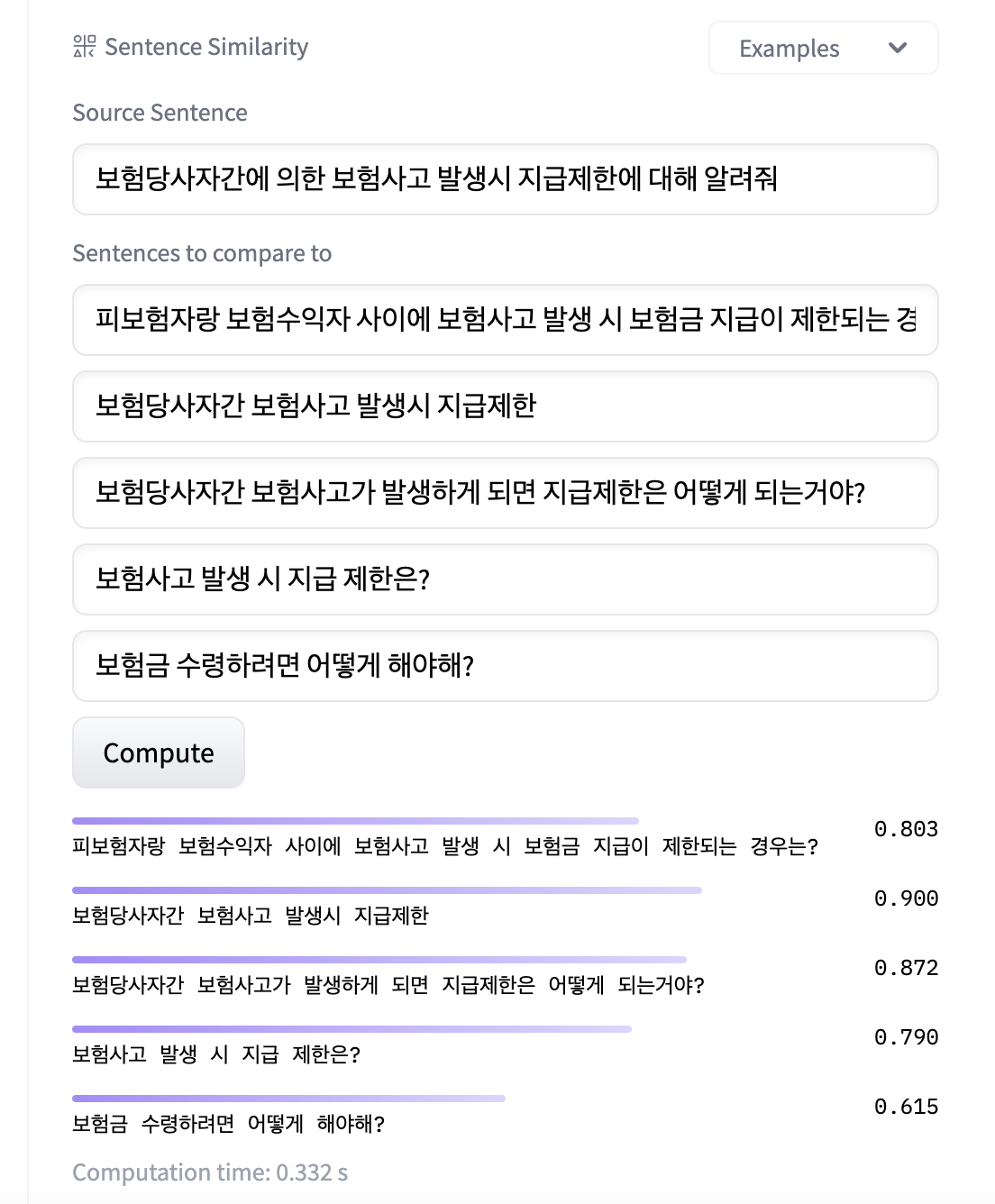
마지막 문장은 패러프레이징한 쿼리라고 보기 어려운데,
이렇게 점수로 봐도 0.615로 유사도가 낮게 나온 마지막 문장은 제외해야 할 것으로 보인다.
임계값을 정하려면 좀 더 많은 데이터에 대해 테스트를 해봐야 하고,
다양한 쿼리쌍에 대해 여러 모델로 비교 테스트를 해보기 위해서 코드를 짰다.
1) Sentence BERT
한국어 문장에 대해 문장 유사도를 계산할 것이기 때문에,
한국어 문장으로 학습된 KR-SBERT를 사용했다.
https://github.com/snunlp/KR-SBERT
GitHub - snunlp/KR-SBERT: KoRean based SBERT pre-trained models (KR-SBERT) for PyTorch
KoRean based SBERT pre-trained models (KR-SBERT) for PyTorch - GitHub - snunlp/KR-SBERT: KoRean based SBERT pre-trained models (KR-SBERT) for PyTorch
github.com
!pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('snunlp/KR-SBERT-V40K-klueNLI-augSTS')
sentences = ["보험당사자간에 의한 보험사고 발생시 지급제한에 대해 알려줘", "피보험자랑 보험수익자 사이에 보험사고 발생 시 보험금 지급이 제한되는 경우는?"]
vectors = model.encode(sentences) # encode sentences into vectors
similarities = util.cos_sim(vectors, vectors) # compute similarity between sentence vectors
print(similarities)
>>> tensor([[1.0000, 0.8137],
[0.8137, 1.0000]])
1) BGE-M3
BGE-M3는 임베딩 모델로 아래와 같이 3가지 검색 방식을 지원한다.
- Dense retrieval: map the text into a single embedding, e.g., DPR, BGE-v1.5
- Sparse retrieval (lexical matching): a vector of size equal to the vocabulary, with the majority of positions set to zero, calculating a weight only for tokens present in the text. e.g., BM25, unicoil, and splade
- Multi-vector retrieval: use multiple vectors to represent a text, e.g., ColBERT.
아래는 BGE-M3로 문장 유사도를 계산하는 코드이다.
!pip install -U FlagEmbedding
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True)
sentences_1 = ["보험당사자간에 의한 보험사고 발생시 지급제한에 대해 알려줘"]
sentences_2 = ["피보험자랑 보험수익자 사이에 보험사고 발생 시 보험금 지급이 제한되는 경우는?"]
sentence_pairs = [[i,j] for i in sentences_1 for j in sentences_2]
print(model.compute_score(sentence_pairs,
max_passage_length=128, # a smaller max length leads to a lower latency
weights_for_different_modes=[0.4, 0.2, 0.4])) # weights_for_different_modes(w) is used to do weighted sum: w[0]*dense_score + w[1]*sparse_score + w[2]*colbert_score
# {
# 'colbert': [0.78688000759315941],
# 'sparse': [0.1358642578125],
# 'dense': [0.80322265625],
# 'sparse+dense': [0.5807698369026183],
# 'colbert+sparse+dense': [0.6632139682769775]
# }
난 colbert+sparse+dense 3가지 방법을 다 합친 마지막 스코어를 채택.
Sentence BERT보다 낮게 나왔다.
'AI > NLP' 카테고리의 다른 글
| [NLP] Captum 라이브러리로 언어 모델 해석 (0) | 2023.12.01 |
|---|---|
| [LLM] LLM 모델 로컬 경로에 저장하기 + git LFS (0) | 2023.10.19 |
| [LLM] 어떤 소스든, Embedchain으로 나만의 챗봇 만들기! (0) | 2023.10.11 |
| [LLM] 거대언어모델, LLM(Large Language Model) 이란? (0) | 2023.10.06 |
| [ChatGPT] 영어 논문 빠르게 읽는 팁!! ChatPDF를 이용해 PDF 파일 요약 및 질문하기 (0) | 2023.09.27 |




댓글