거대언어모델, LLM 이란?
거대언어모델 (Large Language Model, LLM) 이란 쉽게 말해 대용량 언어 모델을 말한다.

- 대규모 데이터셋으로 학습되었으며 대규모 파라미터를 가진 언어 모델
- 기존의 PLM들을 대규모로 확장하면 성능이 늘어난다는 것을 확인하며, 구글과 페이스북 같은 IT 공룡들의 LLM 경쟁이 심화되었음.
- ‘거대’의 기준이 정해진 것은 아니나, 일부 전문가들은 GPT-3가 학습한 파라미터 개수인 1,750억 개를 들고 있음
- GPT(Generative Pre-trained Transformer)와 BERT(Bidirectional Encoder Representations from Transformers)와 같은 다양한 모델이 있으며, 최근 가장 주목받는 대표적인 LLM으로 ChatGPT와 LLaMA가 있음.
LLM에서 자주 사용하는 용어
아래는 LLM을 다루는 문서 및 논문에서 자주 사용하는 단어의 정의이다.
미리 알아두면 LLM에 대해 이해하는 데에 도움이 될 수 있다.
- 단어 임베딩: 단어들을 고차원 벡터로 표현하여 각 단어 간의 유사성과 관계를 캡처하는 기술
- 주의 메커니즘: 입력 시퀀스의 다양한 부분에 가중치를 부여하여 모델이 중요한 정보에게 집중할 수 있도록 하는 기술
- Transformer: 주의 메커니즘을 기반으로 한 인코더와 디코더 구조의 신경망 모델로, 길이가 다른 시퀀스를 처리하는 데 탁월한 성능
- Fine-tuning LLMs: 사전 학습된 대규모 언어 모델을 특정 작업에 적용하기 위해 추가 학습하는 과정
- Prompt engineering: 모델에 입력하는 질문이나 명령을 구조화하여 모델의 성능을 향상시키는 과정
- Bias (편향): 모델이 학습 데이터의 불균형이나 잘못된 패턴을 포착하여 실제 세계의 현실과 일치하지 않는 결과를 내놓는 경향
- 해석 가능성: LLM이 가진 복잡성을 극복하고 AI 시스템의 결과와 결정을 이해하고 설명할 수 있는 능력
LLM 작동 방식 및 원리
기본적으로 언어 모델은 통계 모델에서 출발했으며,
LLM은 딥러닝의 방식으로 방대한 양을 사전 학습(Pre-trained)한 전이 학습 (Transfer) 모델이라고 할 수 있다.
LLM은 문장에서 가장 자연스러운 단어 시퀀스를 찾아내는 딥러닝 모델이다.
딥러닝 기술을 사용하여, 문장에서 단어와 구문을 인식하고 이를 연관시켜 언어적 의미를 파악할 수 있다.
이러한 과정에서, LLM은 문법 규칙이나 단어의 사전적 의미와 같은 구체적인 규칙은 따르지 않고,
빈도수나 문법적인 특성 등을 학습하여, 문맥상 올바르게 문장을 생성할 수 있다.
즉, 문장 속에서 이전 단어들이 주어지면 다음 단어를 예측하거나 주어진 단어들 사이에서 가운데 단어를 예측하는 방식으로 작동한다.
이러한 인공 신경망 기반의 언어 모델들은 방대한 양의 데이터를 학습하여, 마치 인간처럼 자연스러운 문장을 생성할 수 있다.
대표적인 방식으로 attention 기법을 활용해 언어 모델의 성능을 크게 향상시킨 Transformer가 있다.

transformer에 관한 자세한 설명 은 아래 글 참조
NLP의 핵심, 트랜스포머(Transformer) 복습!
ChatGPT 등장 이후, 지금은 거대 언어 모델 (LLM, Large Language Model)의 전성기라고 해도 과언이 아닙니다. ChatGPT는 GPT 3.5와 같은 LM 모델을 Supervised Instruction tuning과 RLHF 대화형 모델로 파인튜닝한 모델
didi-universe.tistory.com
이처럼 LLM을 학습시키는 방법은 대부분 방대한 양의 텍스트 데이터를 딥러닝 알고리즘에 입력하는 것이다.
이때 일반적으로, 먼저 토큰화(tokenization)과 같은 전처리 과정을 거쳐 문자열 데이터를 분리한 다음,
BERT, GPT, GPT-2, GPT-3, T5 등의 base 모델을 사용하여 학습을 진행한다.
LLM의 역사와 주요 모델
언어 모델은 크게 Encoder 기반 / Encoder-Decoder 기반 / Decoder 기반 3가지 구조로 나뉘는데,
최근 주목받고 있는 ChatGPT나 LLaMA 같은 LLM들은 생성형 언어모델로, Decoder 기반 언어 모델들이다.
Decoder 기반 LLM은 또 OpenAI의 GPT 계열과 Meta(구 페이스북)의 LLaMA 계열로 크게 나뉘는 것 같다.
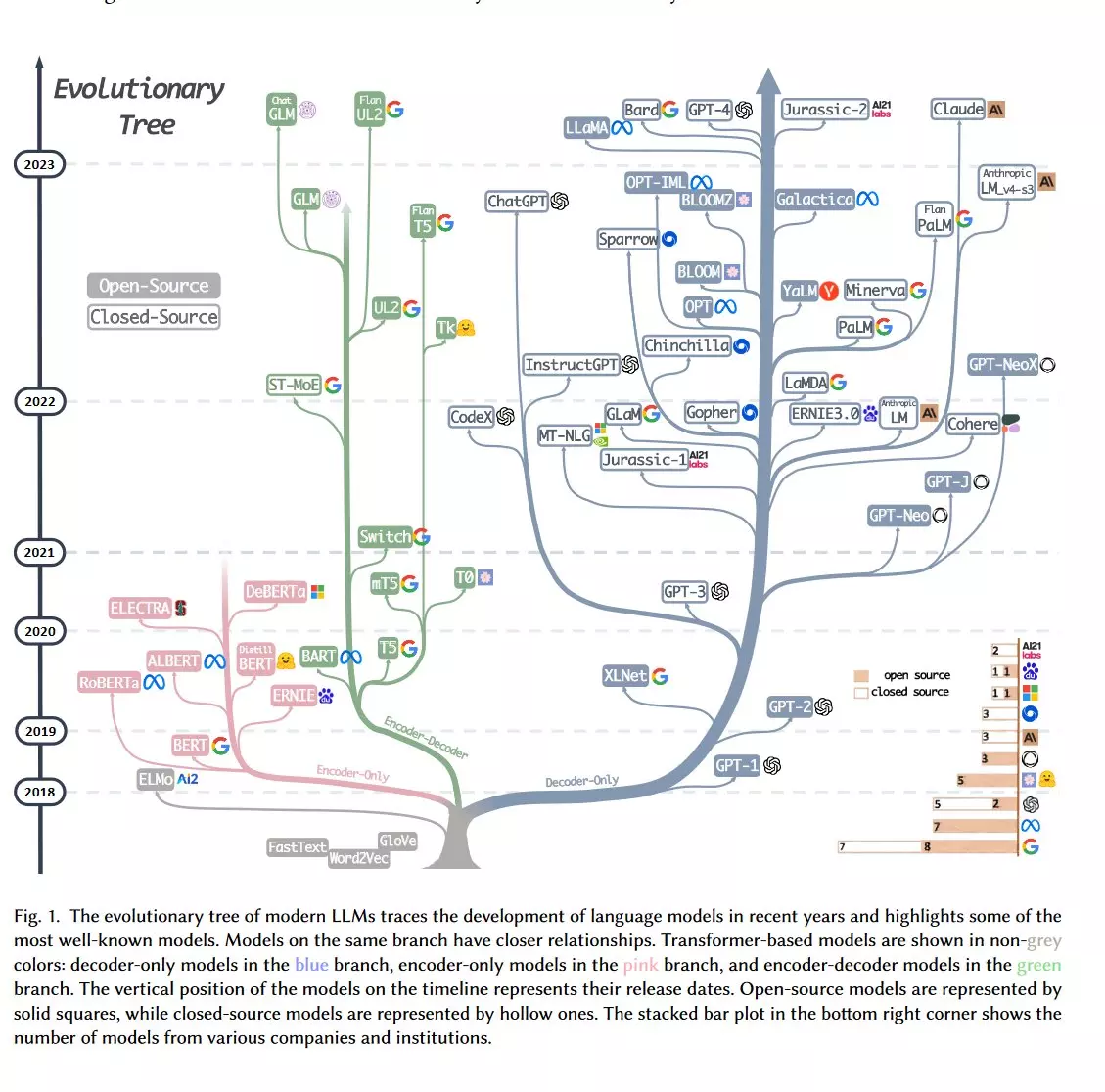
2019년부터 무수히 많은 거대 언어 모델들이 쏟아져 나오고 있다.
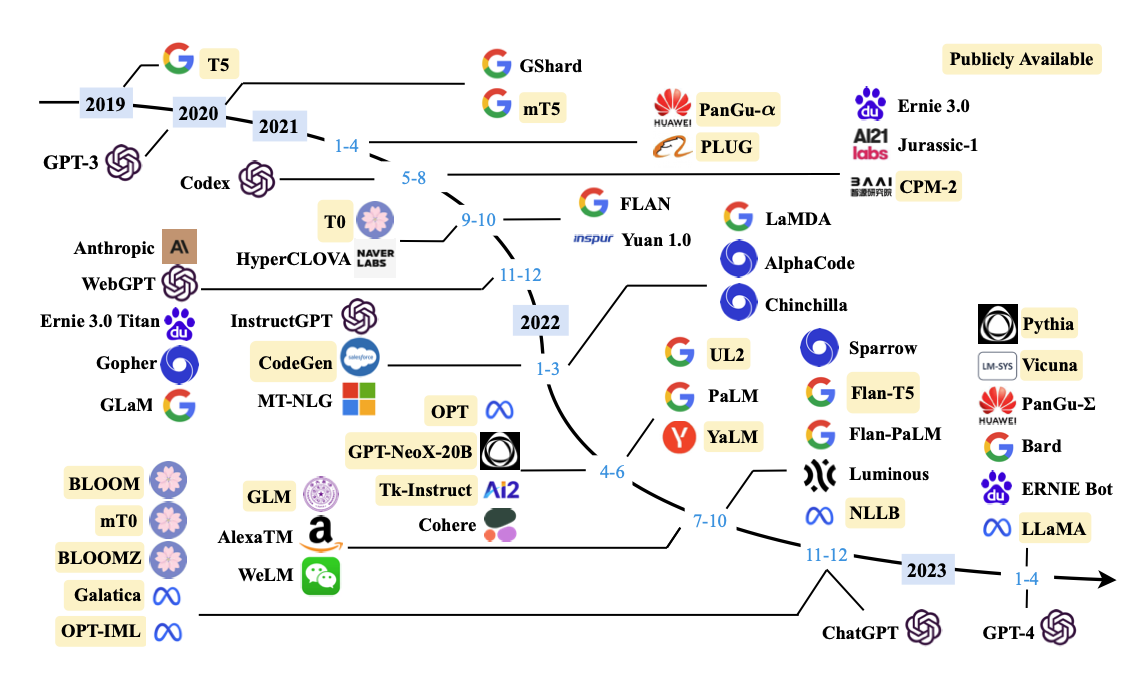
최근 가장 주목 받는 LLM의 핵심 모델은 다음과 같다.
- GPT-3.5 (OpenAI): GPT-3보다 약간의 성능과 안정성을 개선했으며, 광범위한 학습 데이터를 활용해 언어 이해 및 생성 능력을 향상시켜 SOTA를 달성.
- GPT-4 (OpenAI): GPT-3의 후속 모델로, 이전 버전보다 더 큰 모델 크기와 더 정교한 언어 이해와 생성 능력을 갖추고 있음.
- PaLM 2 (Google): Pre-trained Automatic Metrics를 사용한 언어 모델로, 사전 훈련된 언어 모델을 사용하여 기계 번역, 요약, 질문 응답 등의 다양한 NLP 작업에서 성능 평가를 위해 사용됨.
- LlaMA (Meta AI): Language Model Benchmark (LlaMA)에서 개발한 작업 중심 언어 모델로 sota를 달성함. 다양한 자연어 처리 작업을 포함하여 언어 모델의 성능을 평가하고 비교하기 위해 사용됨.
개인적인 생각으로 생성형 LLM의 근본은 GPT이나,
소스코드를 공개하지 않은 OpenAI와 달리 메타는 오픈소스로 공개했기 때문에 활용도가 가장 높은 것은 LLaMA가 아닐까 싶다.
오픈소스 LLM
오픈소스 LLM으로는 다음과 같은 모델들이 공개되어 있다.
- 메타에서 개발한 오픈소스 ‘라마(Llama, Large Language Model Mode AI) 2'
- 뉴아틀라스의 ‘알파카(Alpaca)7B’
- 딥마인드의 ‘쥬라기-1 점보(Jurassic-1 Jumbo)’
- 구글 AI에서 개발한 ‘메가트론-튜링 NLG(Megatron-Turing NLG)’
한국어에 특화된 오픈소스 LLM으로는 튜닙이 배포한 ‘폴리글롯(Polyglot)’이 있다.
LLM 맛보기
오픈소스로 공개되어 있는 LLM 모델을 직접 돌려보고 싶다면
아래 글들을 참고하면 된다!
[LLM] LLM 모델 로컬 경로에 저장하기 + git LFS
[LLM] LLM 모델 로컬 경로에 저장하기 + git LFS
KoR-Orca-Platypus-13B 현재 Ko LLM 리더보드에서 1위중인 KoR-Orca-Platypus-13B 모델 OpenOrca-KO dataset을 활용하여 LLaMa2를 fine-tunning한 모델이라고 한다. - huggingface : https://huggingface.co/kyujinpy/KoR-Orca-Platypus-13B - git
didi-universe.tistory.com
[LLM] Ko-LLM 리뷰, LLaMA2 기반 한국어 파인튜닝 모델 인퍼런스
[LLM] Ko-LLM 리뷰, LLaMA2 기반 한국어 파인튜닝 모델 인퍼런스
Ko-LLM GPT3부터 Llama2에 이르기까지 대규모 언어모델(LLM)의 놀라운 발전은 모든 이의 이목을 끌고 있습니다. 그러나 대규모 말뭉치를 사전학습하는 LLM의 특성상 학습 데이터 중 대다수는 영어로 구
didi-universe.tistory.com
[LLM] 어떤 소스든, Embedchain으로 나만의 챗봇 만들기!
[LLM] 어떤 소스든, Embedchain으로 나만의 챗봇 만들기!
Embedchain 이란? 쉽게 말하면, 어떤 종류의 데이터셋이든 LLM 기반 봇 (Bot)을 쉽게 만들수 있게 도와주는 프레임워크 입니다. - Embedchain 공식 깃헙 : https://github.com/embedchain/embedchain GitHub - embedchain/embed
didi-universe.tistory.com
LLM 평가
그럼 어떤 LLM이 좋은 것인지 평가는 어떤 식으로 이뤄질까?
허깅페이스의 Open LLM 리더보드
벤치마크 데이터를 이용해 성능을 평가하고 그 결과를 공유하는 허깅페이스의 Open LLM 리더보드도 성능 평가를 위해 참고할 수 있는 방법 중 하나이다.
- 허깅페이스 Open LLM 리더보드 : https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4
huggingface.co
허깅페이스의 LLM 리더보드는 Eleuther AI Language Model Evaluation Harness 에 따라 4가지 벤치마크 데이터를 활용해 LLM 성능을 평가한다. 각 벤치마크 데이터에 대한 설명은 다음과 같다.
- AI2 Reasoning Challenge (25-shot) - a set of grade-school science questions.
- HellaSwag (10-shot) - a test of commonsense inference, which is easy for humans (~95%) but challenging for SOTA models.
- MMLU (5-shot) - a test to measure a text model's multitask accuracy. The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more.
- TruthfulQA (0-shot) - a test to measure a model’s propensity to reproduce falsehoods commonly found online. Note: TruthfulQA in the Harness is actually a minima a 6-shots task, as it is prepended by 6 examples systematically, even when launched using 0 for the number of few-shot examples.
Open Ko-LLM 리더보드
한국어 버전 LLM 리더보드도 있다.
업스테이지가 NIA가 공동으로 운영하는 Ko-LLM 리더보드에서도
5개 한국어 벤치마크 데이터셋에 대해 LLM 성능을 평가해서 결과를 공유하고 있다.
- 허깅페이스 Ko-LLM 리더보드 : https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard
Open Ko-LLM Leaderboard - a Hugging Face Space by upstage
huggingface.co
4개 데이터셋은 허깅페이스 LLM 리더보드의 벤치마크 데이터셋을 한국어로 번역한 데이터이고,
나머지 1개 데이터셋은 Ko-CommonGen V2 이라는 데이터셋으로, 고려대학교 NLP&AI Lab에서 scratch부터 제작했다고 한다.
LLM 텍스트 요약 성능 평가
또 LLM을 생성 분야에서 활용을 많이 하다보니,
최근에는 LLM이 생성한 문장을 어떻게 평가할 것인지 대해서도 다양한 연구가 이뤄지고 있는 것 같다.
[LLM] LLM 텍스트 요약 평가 관련 + 논문 리뷰
[LLM] LLM 텍스트 요약 평가 관련 + 논문 리뷰
최근 LLM 모델을 활용한 요약이 BART나 T5 등 기존의 생성 요약 모델을 파인튜닝한 것보다, 심지어 사람이 요약한 것보다 더 좋다는 연구 결과가 나왔습니다. 그런데 이런 요약 모델의 성능 평가는
didi-universe.tistory.com
참고
https://www.thedatahunt.com/trend-insight/what-is-llm
LLM이란 무엇인가? - 정의, 원리, 주요 모델, 적용 사례
LLM (거대 언어 모델, Large Language Model) 은 딥 러닝 알고리즘과 통계 모델링을 통해 NLP 작업을 수행하는 데에 사용합니다. 최근 생성 AI의 가능성이 주목 받으면서, LLM의 시장성과 가치가 더욱 주목
www.thedatahunt.com
http://www.itdaily.kr/news/articleView.html?idxno=215587
[커버스토리] 챗GPT 타고 확산하는 ‘거대언어모델’…sLLM 구축 확대일로 - 아이티데일리
[아이티데일리] 최근 국내 모든 산업군에서 혁신의 아이콘으로 부상한 기술이 있다. 바로 거대언어모델(LLM, Large Language Model)이다. 올해 초 챗GPT(Chat Generative Pre-trained Transformer)가 국내에 실험...
www.itdaily.kr
'AI > NLP' 카테고리의 다른 글
| [LLM] LLM 모델 로컬 경로에 저장하기 + git LFS (0) | 2023.10.19 |
|---|---|
| [LLM] 어떤 소스든, Embedchain으로 나만의 챗봇 만들기! (0) | 2023.10.11 |
| [ChatGPT] 영어 논문 빠르게 읽는 팁!! ChatPDF를 이용해 PDF 파일 요약 및 질문하기 (0) | 2023.09.27 |
| [LLM] LLM 텍스트 요약 평가 관련 + 논문 리뷰 (0) | 2023.09.26 |
| [검색] sentence embedding - KoSimCSE / SimCSE 논문리뷰 (0) | 2023.09.25 |




댓글