업스테이지가 운영중인 허깅페이스 Open Ko LLM 리더보드에 이어, 새로운 한국어 LLM 리더보드가 등장했다.
이름은 호랑이 (Horangi), 아래 링크에 리더보드에 대한 자세한 설명이 나와있으니 참고.
Horangi 한국어 LLM 리더보드
자연어 이해 및 생성 관점에서 한국어 LLM들의 능력을 평가합니다. Made by Kim, Ki Hyun using Weights & Biases
wandb.ai
허깅페이스 Open ko LLM 리더보드에는 현재 업스테이지의 Solar 모델을 dpo로 파인튜닝한 모델들이 상위권을 차지하고 있다.
그런데 과연 이 리더보드는 신뢰할 수 있는 것인가?
항상 LLM 생성문에 대한 평가는 어려움을 겪는 것 같다.
특히 영어에 비해 한국어는 학습 데이터 뿐만 아니라 평가 데이터인 벤치마크 데이터셋도 현저히 적은 편이다.
다행히 최근 KMMLU, Logickor과 같은 한국어 LLM 벤치마크 데이터셋들이 꽤 등장하고 있는데,
LLM 리더보드인 호랑이에는 2가지 벤치마크 데이터셋이 포함되어 있다고 해서 한번 리뷰를 해보았다.
호랑이 리더보드란
아래는 호랑이 리더보드에서 발췌한 설명이다.
호랑이 LLM 리더보드는 거대언어모델(LLM)의 한국어 능력을 평가하기 위한 도구로써 또 다른 대안을 제시합니다. 우리는 두 가지 방법을 통해 한국어에 대한 종합적인 평가를 수행하고자 합니다.
1. Q&A 형식의 언어이해 llm-kr-eval: 일본어 버전인 llm-jp-eval 기반에서 한국어 버전으로 개발되었습니다.
2. Multi-turn 대화를 통해 생성 능력을 평가하는 MT-Bench
호랑이 LLM 리더보드는 Weight & Biases (W&B)의 테이블 기능을 활용하여 평가 결과를 다양한 시각에서 쉽게 분석할 수 있도록 합니다. 이 기능을 활용하면 각 모델 별 비교를 손쉽게 수행할 수 있으며, 기존 실험들을 추적하고 기록할 수 있습니다.
이 문서는 호랑이 LLM 리더보드의 평가 결과와, 평가 방법론, 각 평가 query에 대한 세부 분석을 제공하며, 이를 통해 사용자에게 최신 LLM에 대한 이해도를 높일 수 있도록 하고자 합니다.
호랑이 리더보드 사용법
- 기존에 출시된 유명 LLM들에 대한 평가 결과를 baseline으로 제공합니다.
- 질의응답 형태로 구성된 llm-kr-eval, 프롬프팅 대화에 대한 생성 능력을 평가하는 MT-Bench를 활용한 종합 평가를 수행합니다.
- llm-kr-eval의 경우, 근본적인 능력을 측정하기 위해 제로샷 평가를 수행합니다. 🌶️
- W&B의 테이블 기능을 활용하여 심층 분석을 가능케합니다. 🔍
- 간편한 비교를 위해 interactive한 모델 비교가 가능합니다. 🎰
- 사용자가 원한다면 평가 결과를 리더보드에 공유하지 않을 수 있습니다!
-> 나는 이 중에서, 회사 내부에 있는(외부 공개 안되어 있는) 자체 LLM의 성능을 평가해보고 싶었기 때문에
리더보드에 제출하지 않고 내부에서 소스코드로 평가를 해볼 수 있다는 점이 마음에 들었다!
리더보드 소스코드는 아래 깃헙에서 확인할 수 있다.
LLM 종합 평가 결과
Overall average = (llm-kr-eval + MT-bench/10) / 2
현재 (24.04.08) 기준 리더보드는 다음과 같은 상태이다.
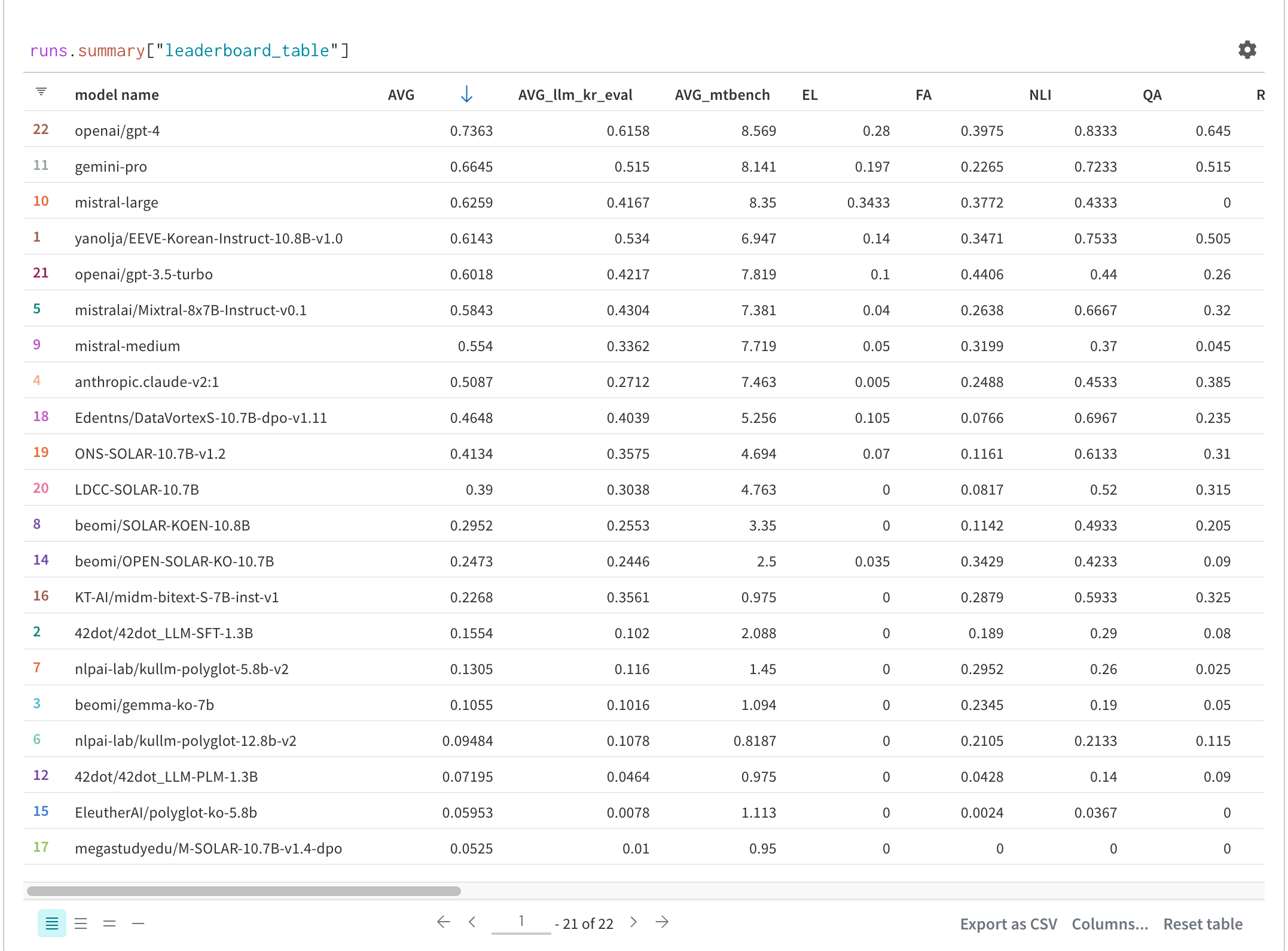
GPT-4가 압도적으로 1위를 달리고 있다.
오픈소스 모델로는 Mistral-large나 야놀자의 EEVE-Korean-instruct-10.8B-v1.0 모델의 성능이 준수한데,
특히 야놀자 모델은 10.8B로 모델사이즈에 비해 성능이 괜찮은 것 같다.
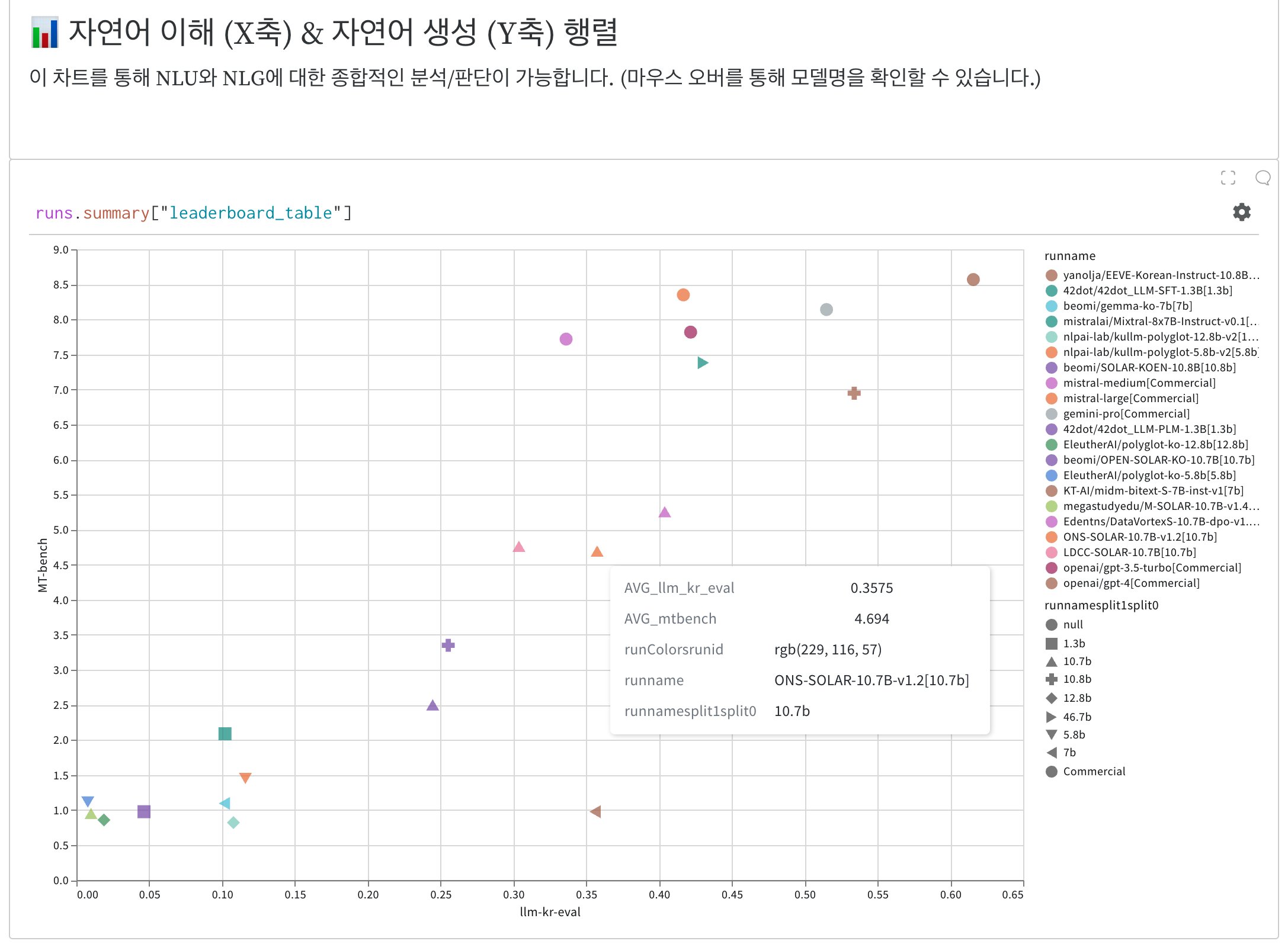
아래 인터랙티브 그래프에서는 전반적으로 자연어 이해 및 생성 관련 모델 성능에 대해 한눈에 파악해보기 좋다.
마우스 커서를 갖다대면 아래와 같이 모델에 대한 설명이 나온다.
모델 사이즈를 도형으로 구분해두었다.
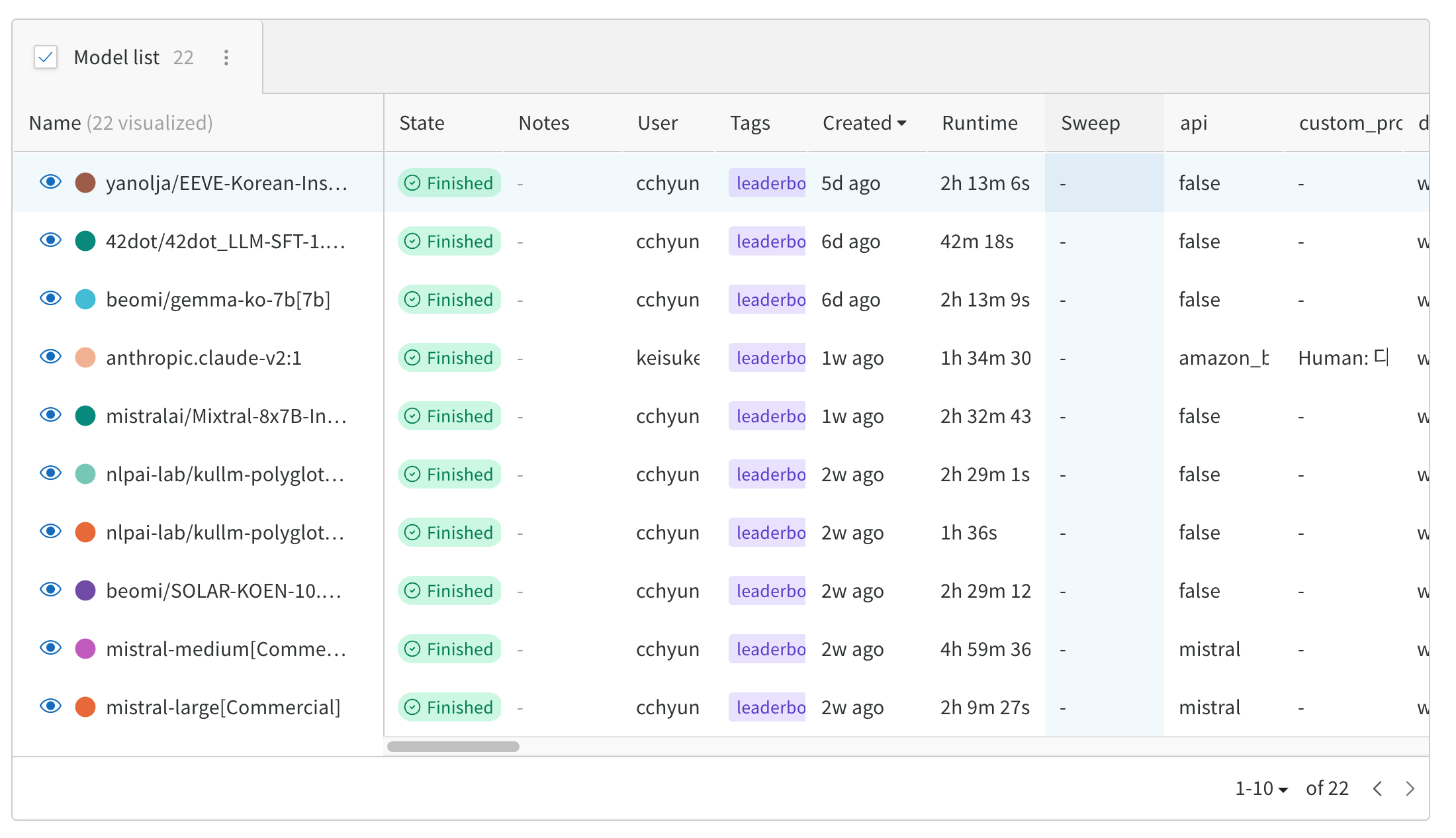
우선 리더보드에 공개된 모델들로 정상동작 여부를 확인하고, 리더보드 기능들을 쭉 살펴보다가
42dot의 42dot/42dot_LLM-SFT-1.3B 모델의 runtime이 42분으로 짧은 것을 확인,
해당 모델로 MT-bech 소스코드 구현을 해보기로 결정!
Korean MT-Bench score 구현은 다음 글에서 이어서 살펴보자.
[다음글] [한국어 LLM 벤치마크] Korean MT-bench score 계산하기 (1)
[한국어 LLM 벤치마크] Korean MT-bench score 계산하기 (1)
한국어 LLM 리더보드인 호랑이에 대해 리뷰를 진행해보고, 외부 오픈소스 모델 및 내부 사내 자체 개발 모델에 대해 평가를 진행해보기로 결정! 호랑이 한국어 LLM 리더보드에 대한 소개는 아래
didi-universe.tistory.com
[다음글] : [한국어 LLM 벤치마크] Korean MT-bench score 계산하기 (2)
[한국어 LLM 벤치마크] Korean MT-bench score 계산하기 (2)
[이전글] : [한국어 LLM 벤치마크] Korean MT-bench score 계산하기 (1) [한국어 LLM 벤치마크] Korean MT-bench score 계산하기 (1) 한국어 LLM 리더보드인 호랑이에 대해 리뷰를 진행해보고, 외부 오픈소스 모델
didi-universe.tistory.com
'AI > LLM' 카테고리의 다른 글
| [한국어 LLM 벤치마크] Korean MT-bench score 계산하기 (2) (0) | 2024.04.15 |
|---|---|
| [한국어 LLM 벤치마크] Korean MT-bench score 계산하기 (1) (3) | 2024.04.08 |
| 대용량 한국어 데이터셋 : Markr AI - KoCommercial Dataset (0) | 2024.04.03 |
| [LLM] Mistral 7B v0.2 Base Model 공개 (2) | 2024.04.03 |
| [NLP] 허깅페이스 모델 캐시 확인하기 (2) | 2024.04.02 |



댓글